NMT Training through the Lens of SMT
This is a post for the EMNLP 2021 paper Language Modeling, Lexical Translation, Reordering: The Training Process of NMT through the Lens of Classical SMT.
In SMT, model competences are modelled with distinct models. In NMT, the whole translation task is modelled with a single neural network. How and when does NMT get to learn all the competences? We show that
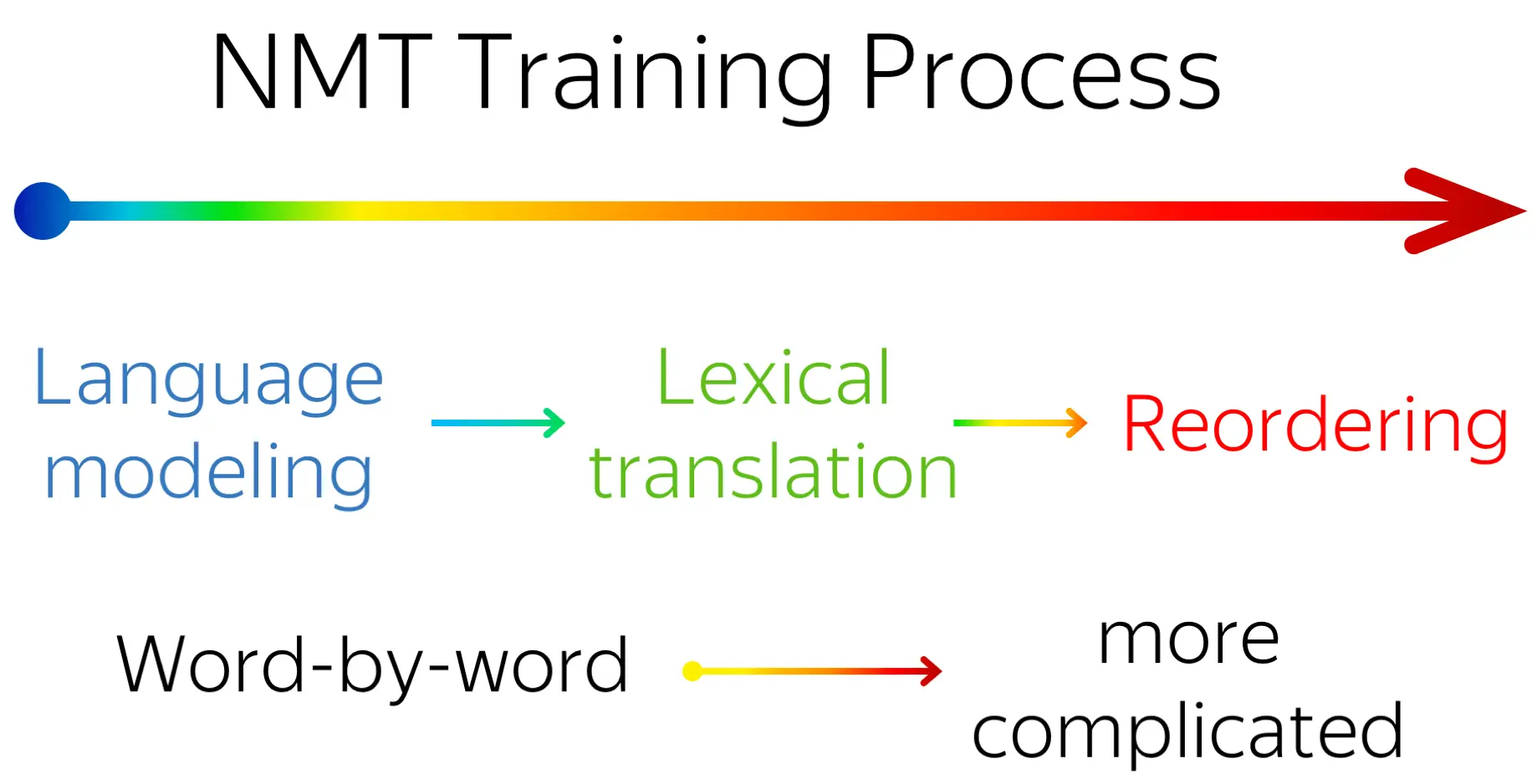
- during training, NMT undergoes three different stages:
- target-side language modeling,
- learning how to use source and approaching word-by-word translation,
- refining translations, visible by increasingly complex reorderings, but almost invisible to standard metrics (e.g. BLEU);
- not only this is fun, but it can also help in practice! For example, in settings where data complexity matters, such as non-autoregressive NMT.
September 2021